Customer Loyalty and Marketing Analytics
Customer Clustering for Data-Driven Insight to Increase Sales
Project Overview
Turtle Games is a company that both manufactures and sells its own products, while also sourcing and retailing products made by other companies. This project analysed 2,000 customer records and customer reviews in order to answer four critical business questions:
1. What influences loyalty points?
2. How can customers be clustered for marketing purposes?
3. How can social data be leveraged?
4. Can prescriptive statistics demonstrate the suitability of loyalty points data to create predictive models?
Toolkit
Python (Jupyter Notebook)
Data analysis and visualization
Pandas & NumPy libraries
Data cleaning, exploration, aggregation, and statistical analysis
Matplotlib & Seaborn libraries
Advanced data visualization to identify patterns
Statsmodels library
Estimate statistical models and perform statistical tests
WordCloud
Presentation of keywords that appear frequently in text data
Methodology
1
Data Import and Quality Assessment
Datasets were imported and exploratory data analysis (EDA) was performed. Data quality was evaluated and opportunities on the basis of the following features: loyalty points, age, remuneration, and spending score. Linear correlations and multilinear regressions were investigated.
2
Decision Trees
A decision tree analysis helped identify the most impactful factors tied to loyalty points, and their role in creating a targeted marketing campaign. The first decision tree attempt turned out to be overfitted (R² score = 1.0); after pruning (R² score: 0.91), the model correctly classified data 91% of the time.
3
K-Means Clustering (Elbow method and Silhouette method)
A pair-plot was created to get a first glance at the best number of clusters. Elbow and Silhouette methods were performed and generated two graphs visually exposing the best cluster number. Two different k-means approaches were performed to identify the best suited for the objective.
4
Sentiment Analysis
Basic EDA was performed on the review data. Word clouds and a line graph revealed the most frequent words. The polarity of the reviews and a summary of the comments were visualized in two different histograms. The top 20 positive reviews and the top 20 negative reviews were analyzed.
5
Synthesis
Quantitative and qualitative were synthesized to address loyalty point accumulation, k-means clustering, and sentiment polarity. A supplementary customer satisfaction score analysis was added.
K-Means Clustering Visualization
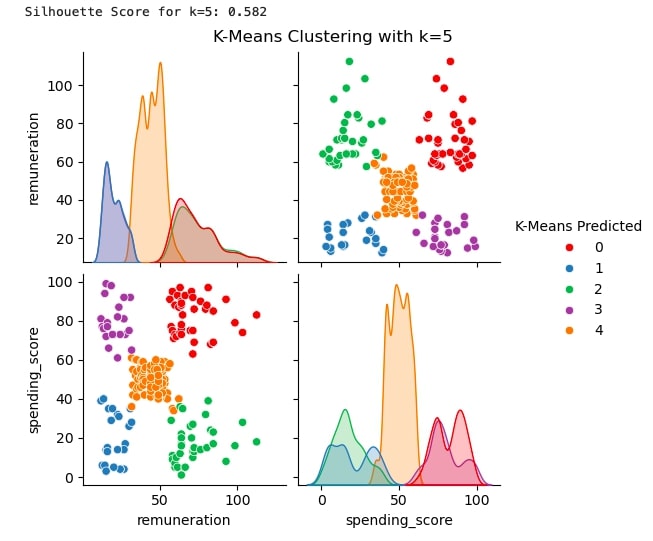
Customer segmentation using K-Means clustering (k=5) based on remuneration and spending score. Silhouette Score: 0.582
Key Insights
-
Loyalty Points and Correlation• Strongly and positively influenced by spending score and remuneration
• Age doesn't really determine loyalty points, but its inclusion in a multiple linear regression improves the fitting of the regression
• Multilinear model can predict 84% of the variance
• Histogram showed a right-skewed distribution, where the majority of customers accumulate relatively low points, while a few outliers earn a vast amount -
Sentiment Analysis• Frequency toward a more positive sentiment than negative sentiment
• Average customer satisfaction score (Summary): 61.18%
• Average customer satisfaction score (Review): 60.66%
Business Recommendations
1
Implement targeted marketing campaigns using 5-cluster segmentation
Clustering revealed that 5 is the best fitting cluster number. This model can support marketing decisions by clustering customers into five groups and creating incentives suited for each: (1) High remuneration and spending, (2) Low remuneration and spending, (3) High remuneration, low spending, (4) Low remuneration, high spending, and (5) Medium remuneration and spending. Tailor messaging, offers, and loyalty rewards to each segment's unique characteristics.
2
Focus loyalty program enhancements on high-spending segments
The multilinear model demonstrates that spending score and remuneration are the strongest predictors of loyalty points (84% variance explained). Prioritize retention efforts for high-spending customers who generate disproportionate loyalty value, while developing strategies to increase engagement among medium and low spenders.
3
Address negative sentiment to strengthen brand reputation
While brand reputation remains strong overall, negative comments in both summaries and reviews reveal areas of improvement. Words like 'boring' and 'disappointing' appear frequently. Investigate product quality issues and negative customer feedback to improve satisfaction scores above the current 61% threshold.
4
Deploy predictive models for customer lifetime value optimization
The decision tree model (91% accuracy after pruning) and multilinear regression (84% variance prediction) demonstrate strong predictive capabilities. These marketing automation models should be implemented to identify early on high-potential customers, optimize acquisition, and personalize engagement strategies based on the predicted loyalty trajectory.
Sentiment Polarity Distribution
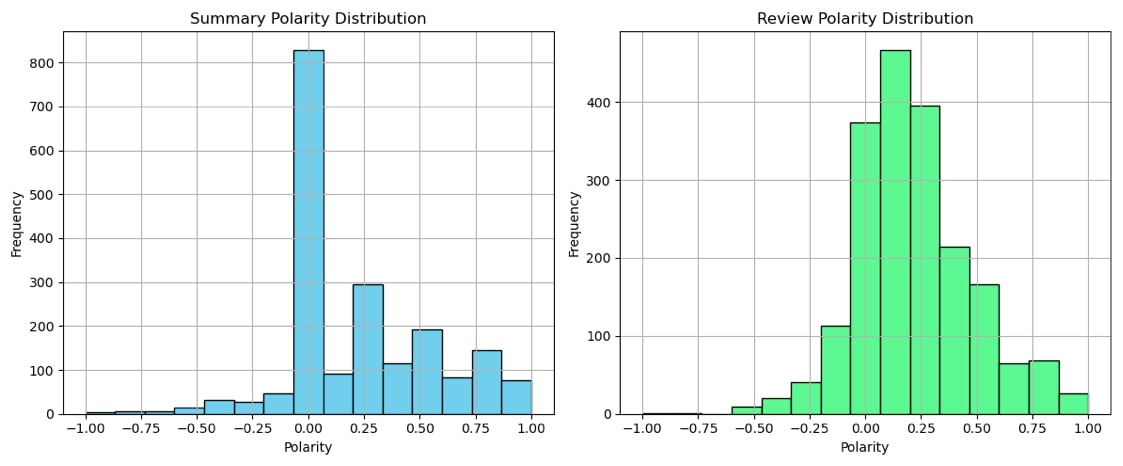
Distribution of sentiment polarity across customer summaries and reviews, demonstrating overall positive sentiment tendency
Download Project Files
Access the complete analysis report and Jupyter notebook with full code implementation.